What is Ada
Ada is Lovelace's Square conversational assistant for chemometrics, designed to help you navigate, learn, and find what you need across the platform.
Beta testing
Ada is currently in beta testing. We are using this stage to evaluate response quality, tool behavior, and edge cases before broader release. If you want to participate, you can contact us at contact@lovelacesquare.org.
The age of conversational AI
Conversational AI has changed how many people approach technical knowledge. Instead of searching across many pages and then assembling the answer alone, users can now ask a question in plain language and receive a response that feels immediate and structured. That has lowered the barrier to entry for many fields, including scientific and technical ones.
At the center of most of these systems is a Large Language Model, or LLM. These models are trained on large collections of text and learn patterns in language, explanation, and structure. When you ask a question, the model does not retrieve truth in the way a database does. It generates a response by predicting what a suitable answer should look like based on those patterns.
One reason this feels so powerful is that an LLM can seem like a compressed form of human written knowledge. Decades of textbooks, research papers, tutorials, and technical discussions can suddenly be approached through a single conversational interface. Seen in that way, this is also a new form of knowledge transfer. Knowledge that would normally take time, access, and experience to navigate becomes reachable through a question. That does not remove the need for verification, but it does change how people approach knowledge and how quickly they can begin working with it.
Seen from that angle, this may be one of the most important revolutions in access to knowledge in the last century, and possibly in human history. Its importance comes from how sharply it reduces the cost of reaching explanations, references, and technical orientation, in many cases pushing that practical cost close to zero. That shift opens a new path for democratizing access to knowledge, making forms of guidance that once depended on institutional access, long training, or many hours of searching and synthesis far more widely reachable.
That makes LLMs very useful, but it also creates limits that matter in scientific work. A model can sound precise while still being wrong. It can produce a reference that looks plausible without having retrieved it from a real source. A common example is the DOI problem. A model may know the title of a paper, the topic, or the authors, and from that it may generate a DOI-like string that looks convincing. But a DOI is not something the model can infer from context. In practice it behaves like an arbitrary identifier, so if it has not been retrieved from a real source, it is not actually known.
There is a second limitation that matters just as much. A general model only knows what was available in its training context. If a new article was published yesterday, or if a platform resource was updated recently, a model working from memory alone will not know that unless the system around it has access to current material. Even when a model is highly capable, depth also varies with size, cost, and configuration. A lightweight model can be very useful, but it may miss the level of nuance required in a specialized field such as chemometrics.
This is where agency matters. By agency, we mean that the system is able to choose actions as part of the response process instead of only generating text from memory. It can decide to search, retrieve, inspect, and continue working with external material before responding. This has become a major direction in the LLM field, because it addresses some of the central weaknesses of model-only answers. Instead of inventing a reference, the system can look for the real source. Instead of relying on frozen training knowledge, it can work with current ecosystem content. Instead of stopping at a generic explanation, it can choose a path that is better matched to the task. In practice, this creates the need for a scientific assistant that is grounded in real material, connected to current sources, and able to act across an ecosystem rather than answer from memory alone. Ada was designed to meet that need.
What is Ada
Ada is the conversational assistant of the Lovelace ecosystem. She is designed for chemometrics and works across The Library and The Square, so a user can ask one question in plain language and continue from explanation into articles, code, datasets, formulas, and practical work without leaving the same conversation.
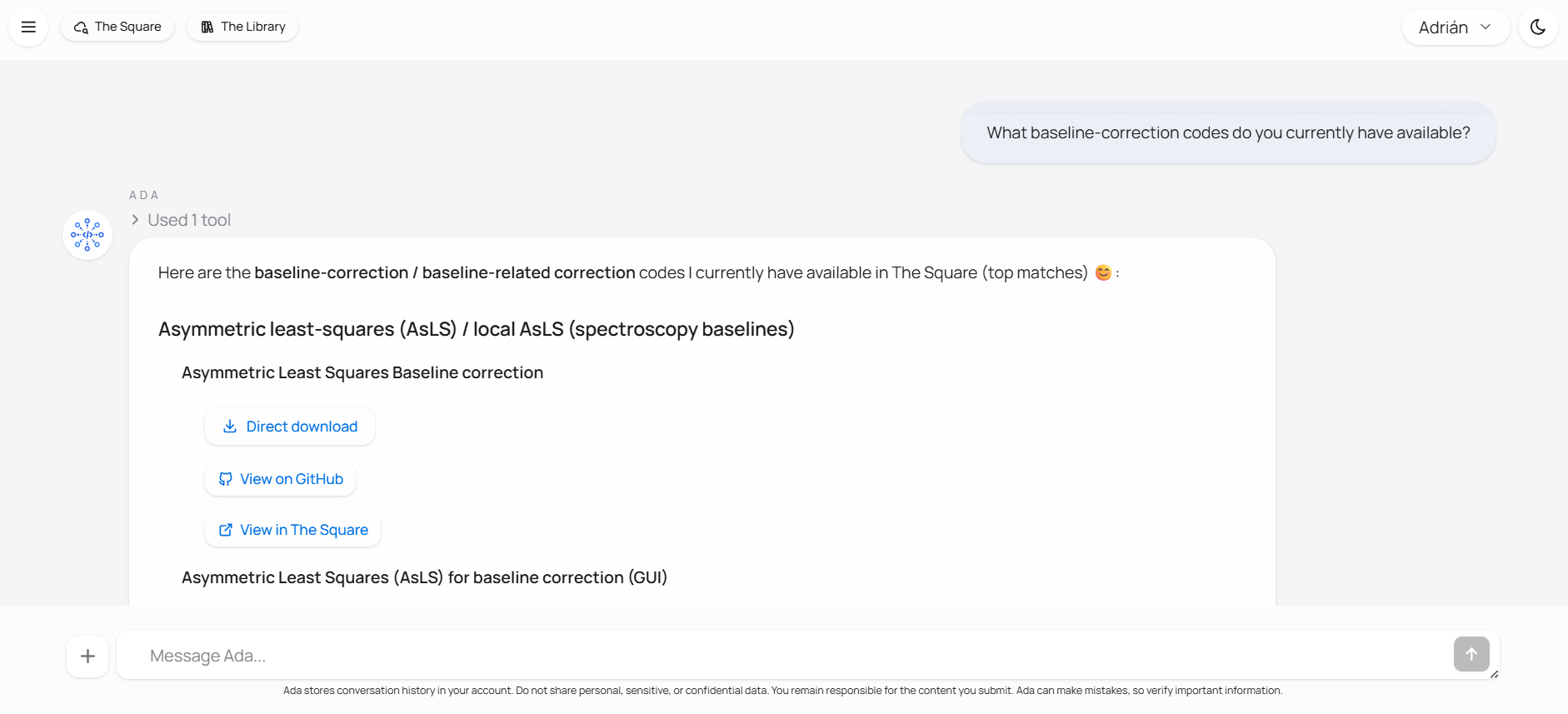
Instead of relying only on a general model response, Ada is built to search the ecosystem and use the retrieved material as the basis of the answer. If you ask for an explanation of a method, she can connect the answer to a Library article. If you ask for a code implementation, she can search The Square. If you ask for the next practical step after reading, she can continue from the same context rather than forcing you to start over somewhere else.
This is the main difference between Ada and a generic chatbot. The goal is not simply to sound knowledgeable, but to keep the response attached to the actual resources of the ecosystem. That does not mean the system is infallible. Ada is still an LLM-based assistant, and answers should still be checked when accuracy matters. The difference is that the system is designed to reduce unsupported responses by grounding them in real platform content and by making the source material easier to inspect.
The home screen below shows the basic interface users start from. The conversation begins in a standard chat view, and from there the session can stay in explanation mode or expand into more practical work when needed.

What Ada can help with
Ada is useful when the question is connected to chemometrics and to the resources of the Lovelace ecosystem. A conversation can begin with a conceptual question, continue into a specific article or code entry, and then move into practical work without changing tools. That matters because chemometric work rarely stops at a definition. A user often needs to understand a method, locate a reliable explanation, inspect an implementation, compare alternatives, and then test or adapt something in practice.
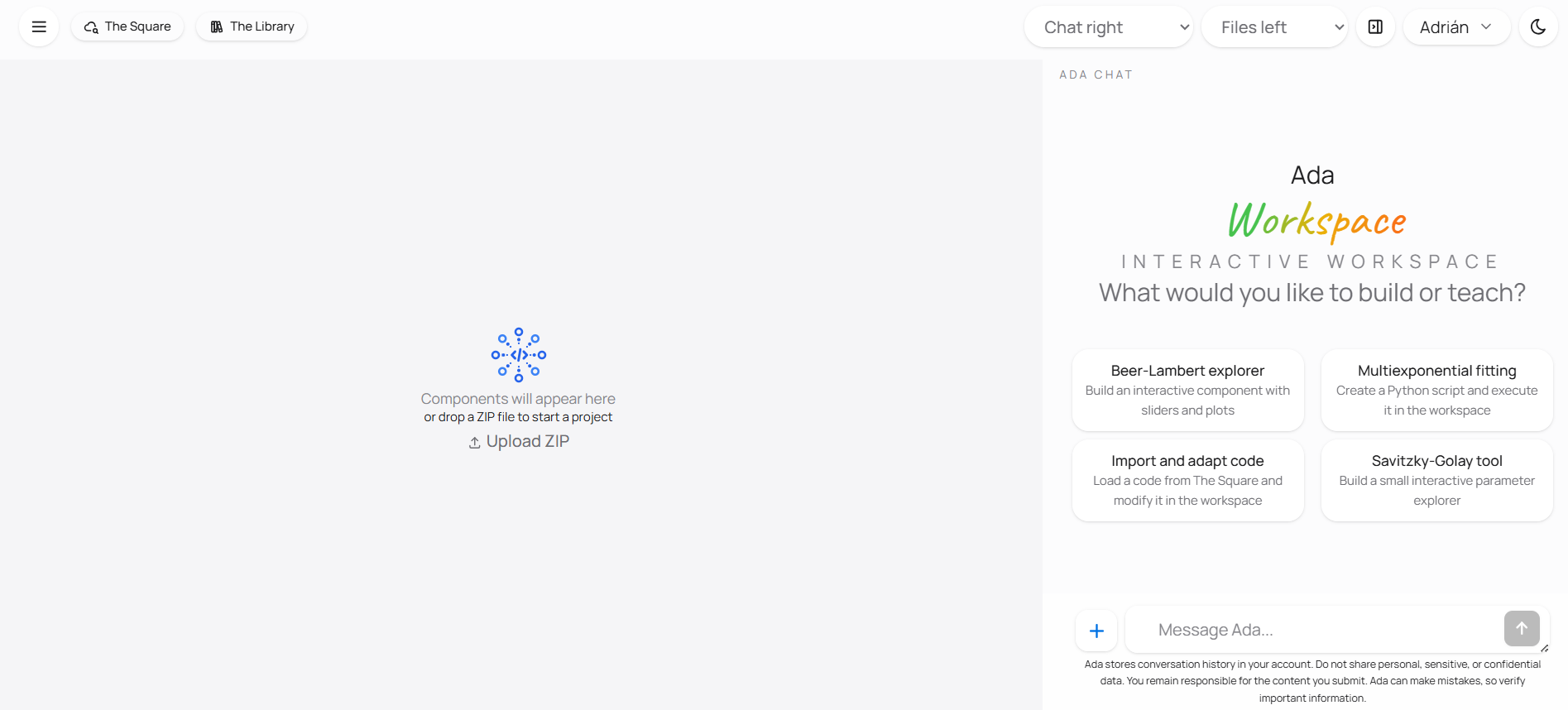
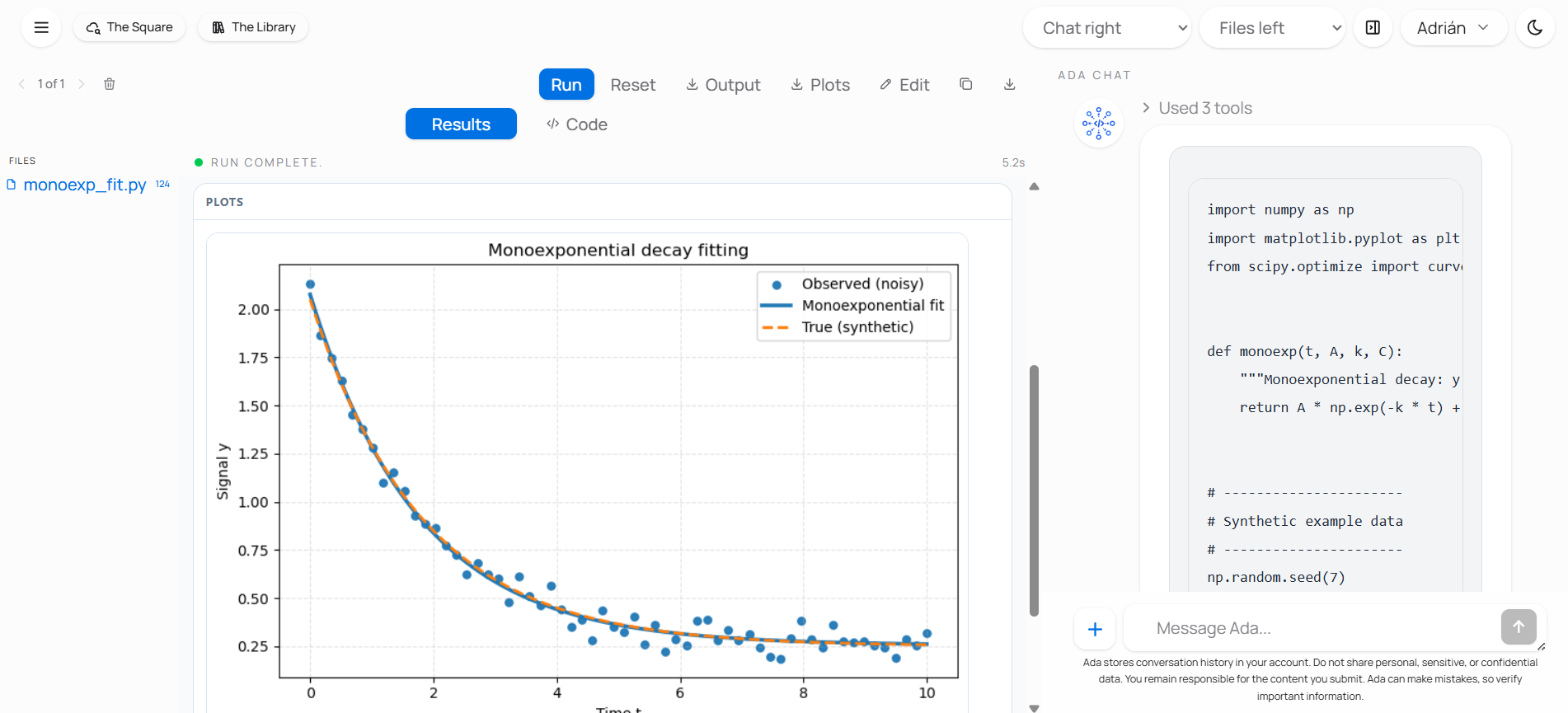
On the retrieval side, Ada can help locate Library articles, code entries, datasets, and other ecosystem resources that match a question. On the explanatory side, she can unpack formulas, clarify methods, compare preprocessing choices, and rephrase difficult material at a more useful level. On the practical side, she can open the workspace and continue from discussion into construction. That includes building interactive components, bringing code into the workspace, and executing Python so the conversation can lead into a real result rather than ending at a static answer.
The important point is that these are not separate utilities presented as unrelated features. They belong to one continuous workflow. A user can begin by asking where to read about a method, then ask for code related to it, then ask Ada to open the workspace and build a small interactive teaching component or run a Python example. That continuity is one of the main reasons Ada is useful inside the Lovelace ecosystem.
How Ada works
At a general level, Ada works through orchestration. That means there is a layer around the model that decides what kind of information the question requires and what actions are worth taking before an answer is returned. The response is therefore not meant to be a single model guess produced in isolation. If a request is mainly conceptual, the system may retrieve explanatory material. If it is resource-oriented, the system may search The Library or The Square. If the first retrieval step is not enough, the system can continue searching, inspect what it has found, and only then compose a response.
This orchestration is tied to Ada's tools. A tool is a concrete capability the system can invoke while answering. Ada uses tools to search the ecosystem, retrieve relevant material, inspect results, and use that material to support the answer. One question may call for a Library article, another for a code entry, another for a dataset, and another for a formula to be explained in context. The user does not need to choose a separate utility in advance. You can ask naturally, and Ada can decide which path is appropriate.
Ada chat is the conversational layer where this process begins and where the context is carried forward. A user can start with a broad question, ask for a more precise explanation, move into a specific resource, and keep refining the discussion without resetting the session. That continuity matters because scientific work often develops step by step. The system can keep the thread of the conversation, which allows explanation, retrieval, and follow-up questions to remain connected.
Ada workspace is the part of the system that extends the conversation into practical work. When a static answer is not enough, Ada can open the workspace so code, results, and discussion stay in the same flow. She can bring project files into that space, help build interactive components, and execute Python when the next useful step is computational rather than descriptive. This is what allows the interaction to move from explanation into construction, inspection, and execution without forcing the user to leave the conversation and start over somewhere else.
Built for chemometrics
Ada is built specifically for chemometrics, which changes both the language of the interaction and the kind of help that is useful. The system is not meant to be a general-purpose assistant covering every topic equally. It is meant to work well in a domain where concepts, preprocessing decisions, formulas, code implementations, and datasets are closely connected.
That specialization matters because many chemometric questions are not satisfied by a generic answer. A user may need to understand a method, see how it is implemented, compare it with another one, and then test it in a small example. Ada is useful because it is attached to an ecosystem built around those needs rather than to the open web in general.
As the ecosystem grows, Ada's useful scope grows with it. New Library content, new code entries, and new datasets expand what the assistant can retrieve and connect. The assistant is therefore not defined only by the model behind it, but by the quality and structure of the chemometric material it can work with.
What Ada is not
Ada should be understood as a documentation and workflow assistant, not as an authority that replaces source checking. She is there to help users orient themselves, retrieve relevant material, and move more efficiently from question to practice. When a claim, a citation, a code path, or a result matters, the original source should still be inspected directly.
That is not a weakness unique to Ada. It is the responsible way to use any LLM-based system in scientific work. The aim is not to eliminate judgment, but to support it with a better interface to the material that already exists in the ecosystem.